准备有三个文件夹,方便理解使用脚本
data:数据集
准备一个车辆数据集,放在data/car/文件夹中。
数据集内JPEGImages有2100张图片,Annotations有2100张xml文件。
train_code:数据处理脚本
在train_code文件夹中,有三个python文件,主要使用的是get_labels.py和main.py两个脚本。
get_labels.py脚本,可以直接获取Annotations文件夹中,所有标注文件的标注类别。
main.py脚本,可以将之前标注文件和图像,进行处理,转换成Yolov5可以训练的格式。
查看自有数据集中的类别数
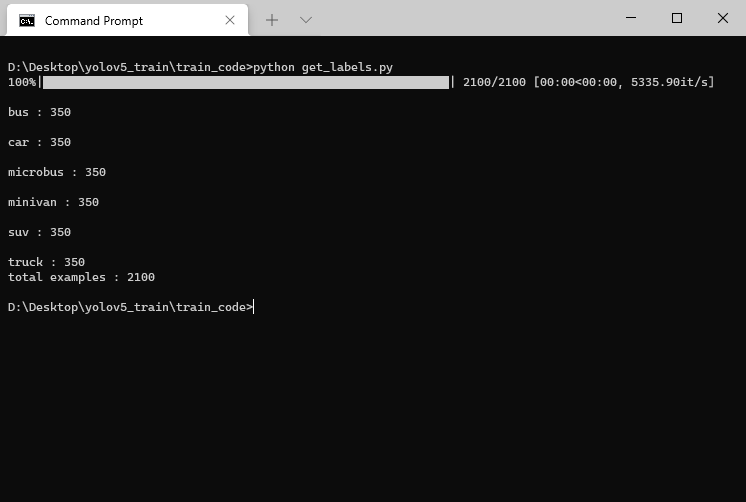
打开train_code/get_labels.py,修改下方的人头数据集路径。
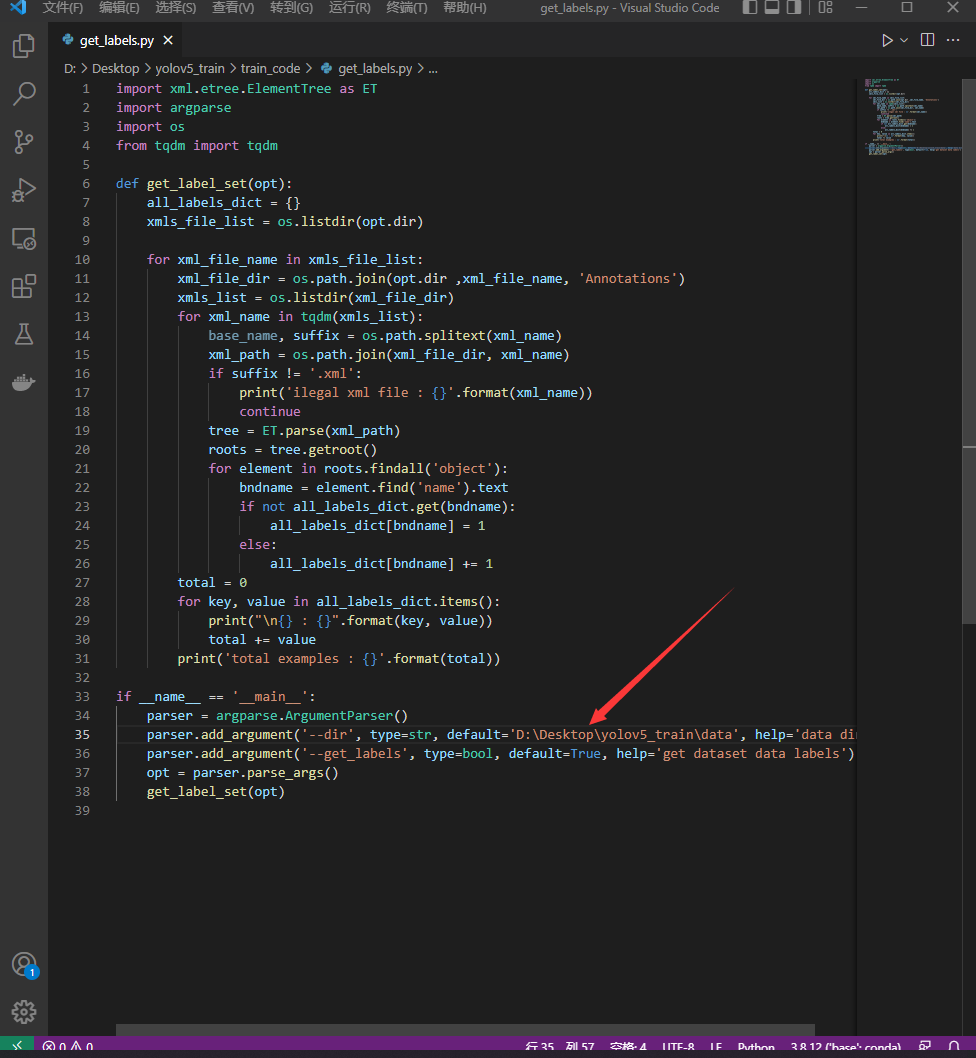
运行后,在下方就可以看到类别数量,以及标注的类别框的数量。
转换训练数据格式
新建数据集转换文件夹
首先在data文件夹里面,新建一个head_train_data文件夹。
并在head_train_data文件夹中,新建一个images_label_split文件夹。
并将前面的car数据集,直接拷贝到images_label_split里面。
main.py脚本处理:配置修改
打开train_code/main.py文件,修改训练数据的路径。
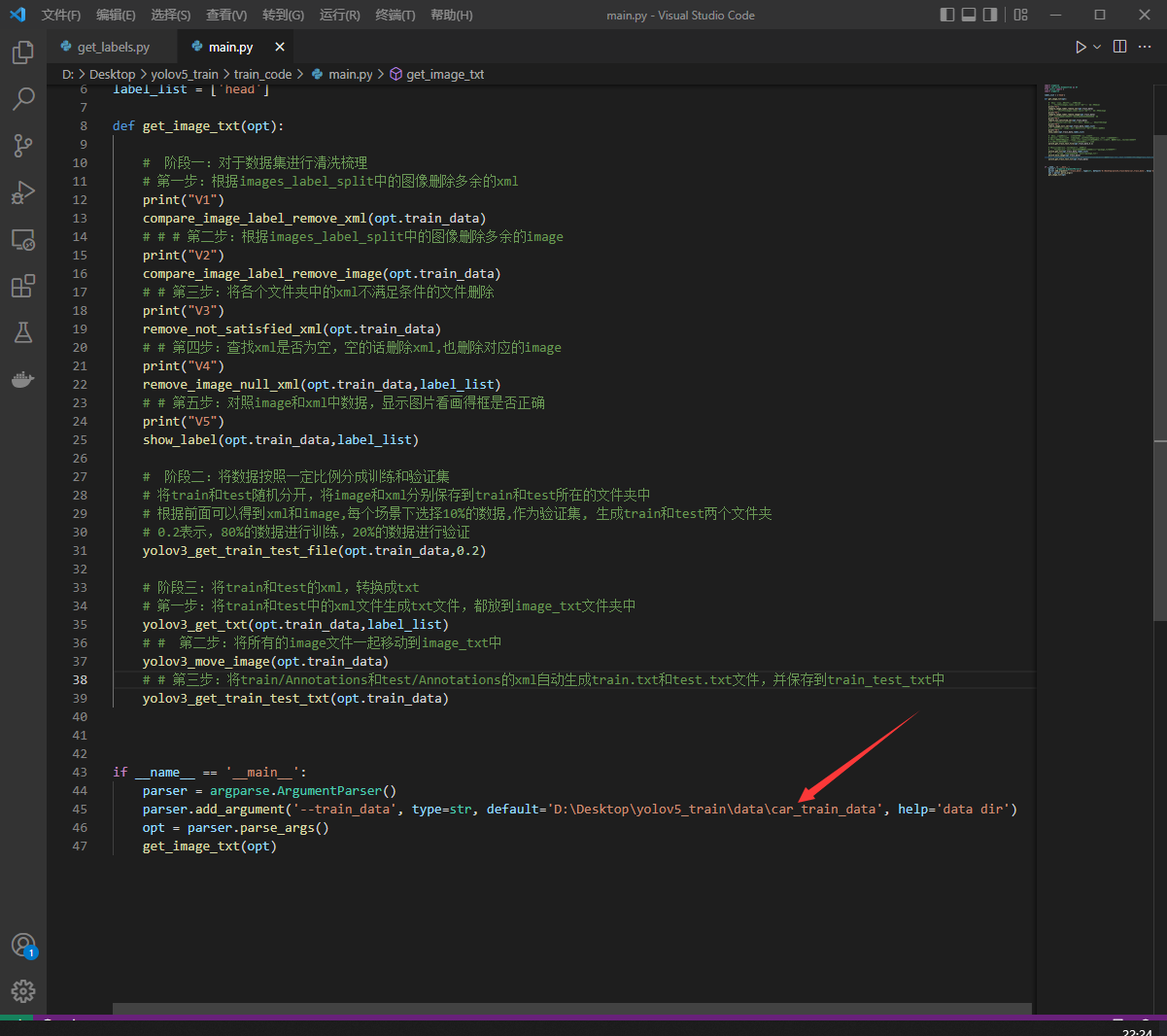
在前面通过get_labels.py脚本,我们也知道了当前数据集的类别数,比如是['bus','car','microbus','minivan','suv','truck'],将该类别填入label_list中。
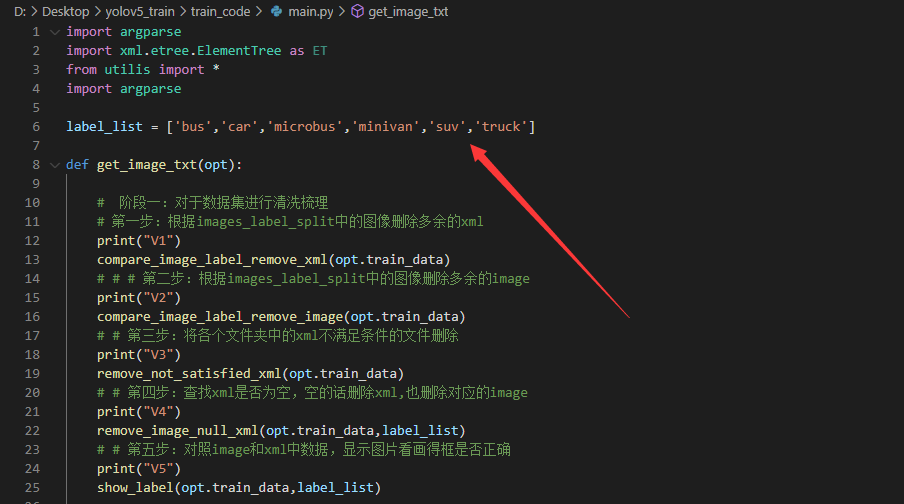
而main.py文件主要分为三个部分的功能:数据集的清洗、训练集&验证集划分、xml转换txt格式。
main.py脚本处理:数据集清洗
数据集的清洗使用的主要是这些行的代码。
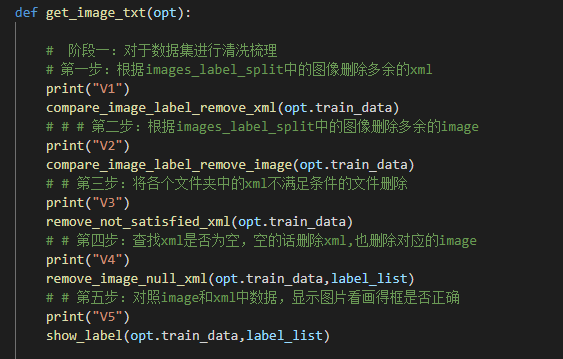
有的数据集有图片,没有标注文件。有的数据集有标注文件,图片有可能丢失。
同时将长宽比太小的框删除掉,并且在删除后,检查下是否存在空的标注文件,如果有,也删除。
并在最后,将标注的框显示到图片上,进一步确定脚本是否正确。
运行上面的代码,最后会跳出来一些画了框的车辆图片,按q键退出查看标注情况,按其他任意键可查看下一张。
在这里需要强调一点,图像出现后必须把光标移动到窗口上再按键才会退出,这是很多初学者常常忽视的地方,如果在终端内按q是无效的。

main.py脚本处理:训练集&验证集划分

0.2表示,80%的数据进行训练,20%的数据进行验证。
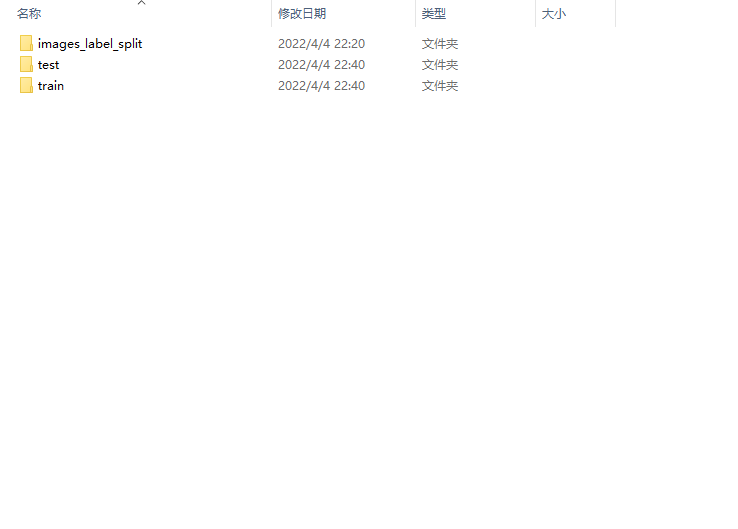
运行结束后,会发现head_train_data这个文件夹下面多了两个文件夹,train和test,就是按照80%、20%进行划分。
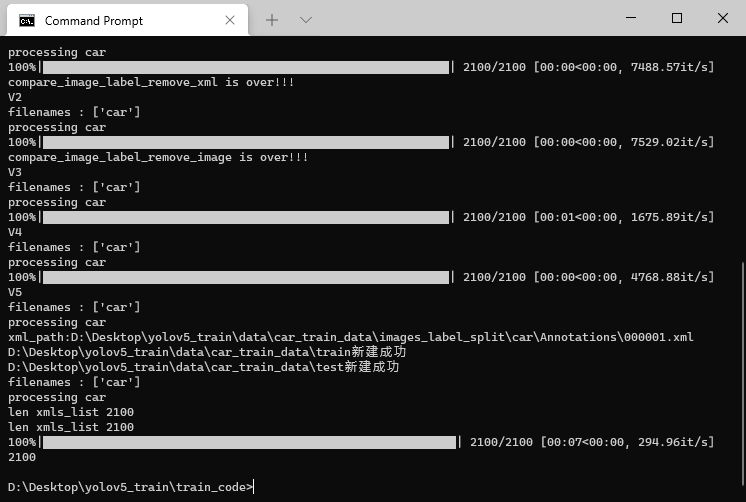
main.py脚本处理::xml转换txt格式
xml转换成txt格式的代码主要是下面三行。

运行结束后,可以看到多了两个文件夹。
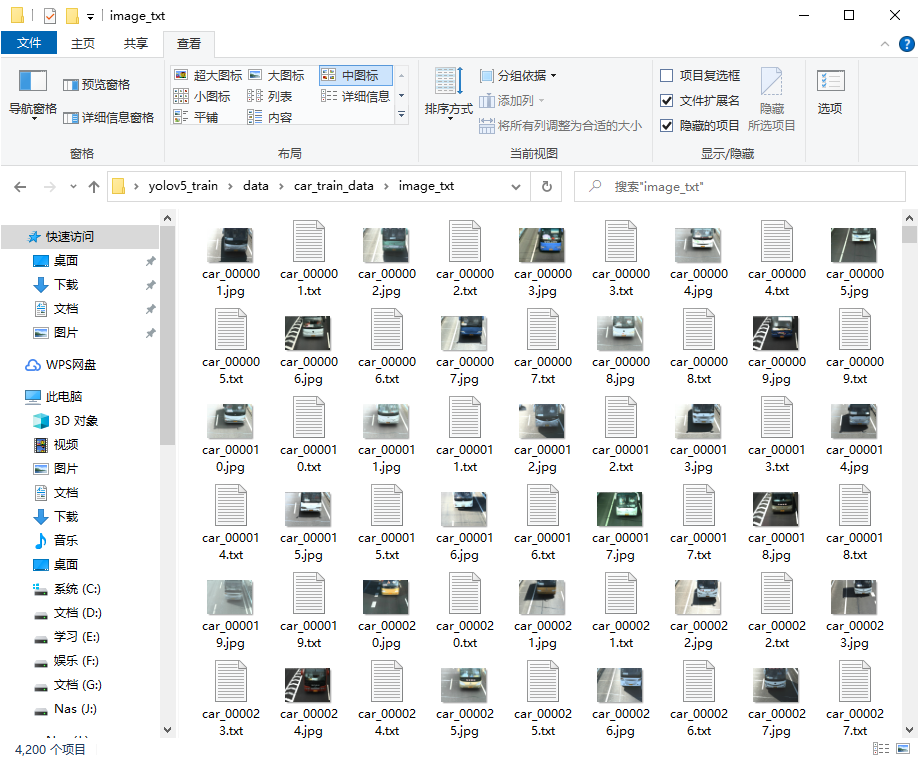
image_txt文件夹中是所有的image和转换完的txt文件。
而train_test_txt文件夹中,则是对于训练和测试数据路径汇总的两个txt,后面训练中会用到。

Yolov5代码训练
修改训练配置
新建一个yaml文件
因为是训练人头数据集,所以在data文件夹下先新建一个car.yaml文件,并修改其中的参数。
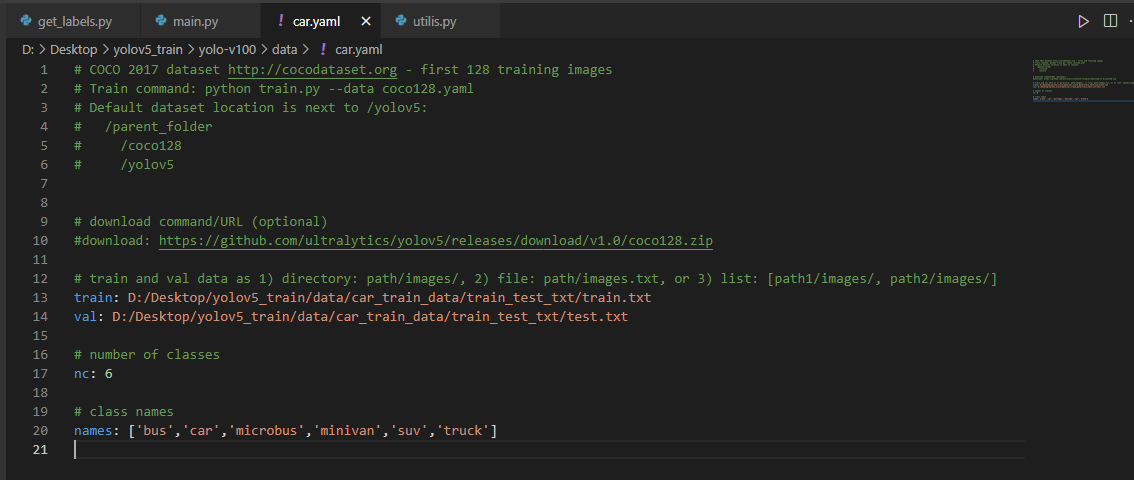
可以复制一个coco128.yaml文件进行修改,其中主要涉及到训练集的txt文件、验证集的txt文件、类别数量nc、类别标签名。
修改train.py参数
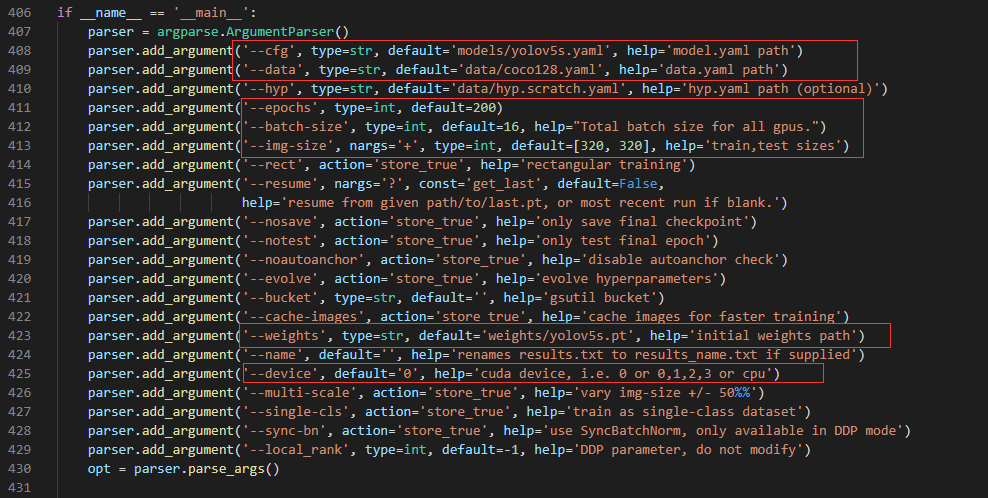
① 修改models里面的weights路径,下载了一些pt文件放在models中,可以选择使用。
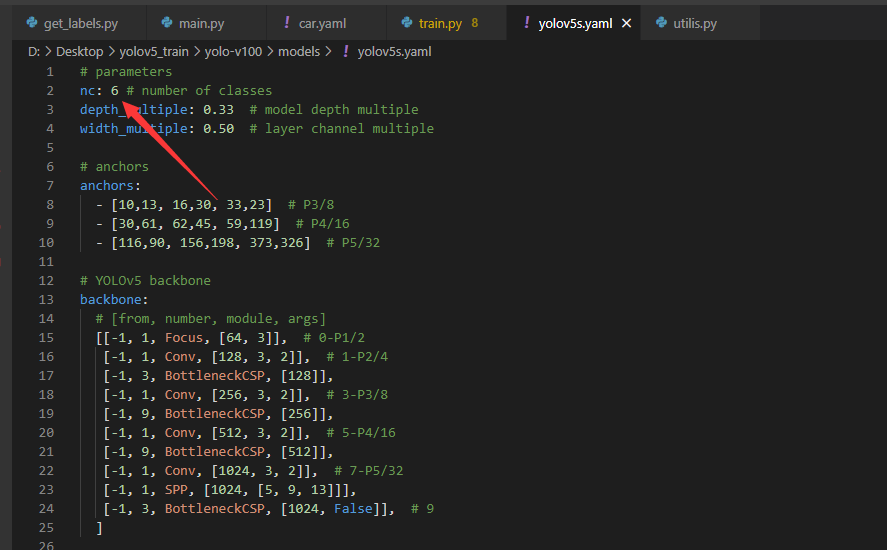
② 修改cfg路径,即网络结构的参数配置文件,需要注意的是,需要修改其中的类别数。
③ 修改data的路径,即前面修改的car.yaml文件。
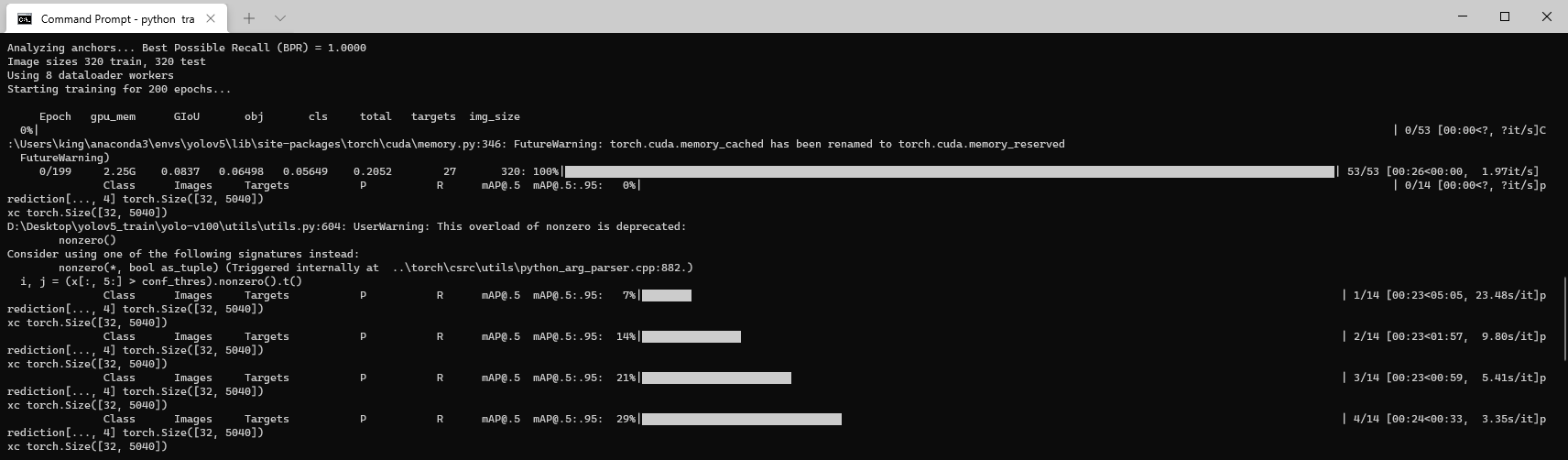
开始训练
运行train.py文件,既可以开始训练。
训练结果测试
网络训练到一段时间后,可以使用detect.py脚本对于训练的模型,进行测试了,不过需要修改是四个参数:
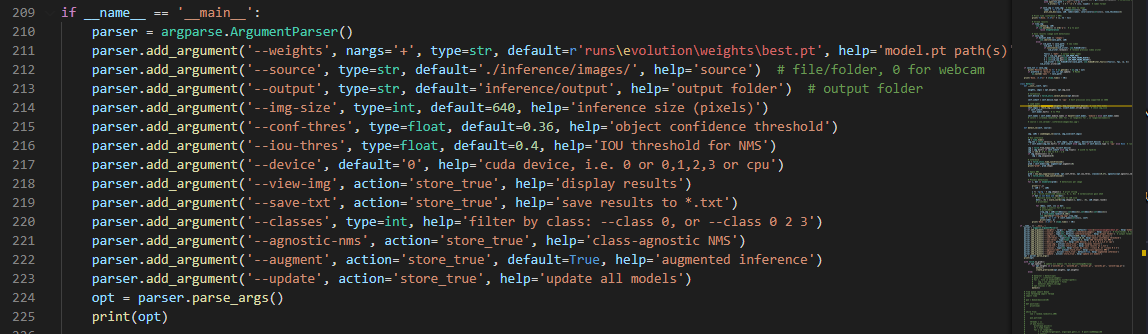
① weights:即前面训练好得到的权重文件
② source:即需要检测的图片数据集
③ data:修改成car.yaml
④img-size:修改成和训练时设置的一样,320或者是640
运行detect.py文件后,可以在inference/output文件夹中得到检测的效果图片:
以上就是Yolov5的详细训练过程,其中每一步都是经过详细的测试的,可以下载对应的代码、权重,进行尝试。


